국내 빅데이터 분석법 정리(서울시장 후보, 송영길-오세훈 비교)
1. 국내 빅데이터 점유율
빅데이터 하면 구글트렌드만 떠오릅니다. 그러나 국내 포털시장은 3개의 대장이 전체의 94%이상을 점유하고 있습니다. 바로 네이버, 구글, 다음입니다.
현재 점유율은 네이버 62%, 구글 26% 다음 4~5% 정도입니다.
InterTremd
InternetTrend™
www.internettrend.co.kr
이 세 포털사이트는 각각 검색량 관련 빅데이터를 제공합니다.
네이버 데이터랩
네이버 데이터랩
네이버의 검색 트렌드 및 급상승검색어 이력, 쇼핑 카테고리별 검색 트렌드 제공
datalab.naver.com
구글트렌드
Google 트렌드
trends.google.com
다음 카카오트렌드
카카오데이터트렌드: 검색어 인사이트
datatrend.kakao.com
2. 점유율 가중합산법
세 포털에서 검색량을 추출해서 단순히 합산만 하면 될까요? 그렇지 않습니다. 각 포털사이트마다 점유율 차이가 있는데 단순합산을 하게 되면 정보가 왜곡될 수 있습니다.
점유율이 높다는 것은 그 만큼 더 많은 사용자가 사용하고 있다는 것입니다. 즉, ‘높은점유율 = 많은 사용자 = 높은 검색량’라는 등식이 성립합니다.
가장 많은 점유율을 가진 네이버 빅데이터에 큰 가중치를 두고 점유율 5%인 다음은 더 적은 가중치를 줘서 합산하는게 합리적입니다.
그래서 점유율 가중합산이라는 방법을 도입했습니다. 아래와 같은 상황을 가정해보겠습니다.
| 구분 | 점유율 | A | B | C |
| 네이버 | 60% | 50% | 30% | 20% |
| 구글 | 30% | 30% | 40% | 30% |
| 다음 | 10% | 20% | 10% | 70% |
| 가중합산 | 41% | 31% | 28% |
A, B, C에 대한 각각 포털사이트의 점유율을 근거로, A의 가중합산 실제 검색율은 네이버 검색량의 60% + 구글 검색량의 30% + 다음 검색량의 10%를 가중치로 합산하는 것입니다.
◀ A=50*0.6+30*0.3+20*0.1=41%
◀ B=30*0.6+40*0.3+10*0.1=31%
◀ C=20*0.6+30*0.3+70*0.1=28%
다음에서는 C의 검색량이 제일 높지만 전체적인 점유율이 10%로 낮기 때문에 큰 영향을 끼치지 못하는 것입니다. 일단 데이타 분석의 큰 골격인 점유율 가중합산은 위와 같은 방법으로 얻어집니다. 특정 한 포털사이트만의 빅데이터는 데이타 편향이 생기기 쉬우므로 세개의 포털사이트의 빅데이터를 가중합산 방식으로 합쳤을 때 좀더 정확한 분석이 가능하다고 판단됩니다.
3. 과거 선거결과로 신뢰성 검증하기
포털사이트의 검색량 차이가 실제 지지율/득표율과 직접적인 연관이 있다고 단정할 수 있을까요? 충분히 합리적인 의심입니다. 그래서 과거 선거결과를 위와 같은 방법을 통해 검증해봤습니다, 4.7서울시장 재보궐선거의 예를 들어보겠습니다.
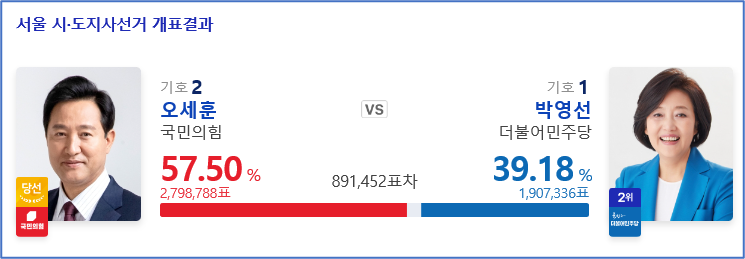
오세훈 vs 박영선 후보의 실제득표율은 57.5% vs 39.2% 였습니다. 두 후보의 득표율 합이 96.8%이기 때문에 이것을 100%로 환산을 합니다. 다른 군소후보의 영향력은 빼고 두 후보의 영향력만 계산하기 위함 입니다. 그러면 59.5% vs 40.5%가 나옵니다. 그리고 포털사이트의 검색량도 두후보의 합을 100%로 환산해서 맞춥니다
이것을 네이버, 구글, 다음 세 포털의 검색량 차이와 비교를 해보겠습니다. 일간데이터는 들쭉날쭉하기 때문에 선거 1주일 전의 검색량 총합으로 확인을 해겠습니다.
| 3.31~4.6 | 점유율 | 오세훈 | 박영선 |
| 네이버 | 55.6% | 61.9% | 38.1% |
| 구글 | 38.6% | 52.9% | 47.1% |
| 다음 | 4.9% | 58.5% | 41.5% |
| 가중합산 | | 57.9% | 42.1% |
| 실득표율 | | 59.5% | 40.5% |
결과는 위와 같습니다. 가중합산 결과는 구글이나 네이버의 특정 빅데이터 결과치보다 훨씬 실제 득표율에 가깝게 수렴합니다. 이런 분석방법이 의미가 있다고 보는 이유입니다
4. 각 포털의 진보/보수 편향, 왜곡율
위 데이터를 자세히 보면 네이버는 실제 득표율보다 오세훈 후보의 검색량이 높았고 구글은 여전히 오세훈이 높긴 하지만 좀 더 박빙양상으로 나타납니다. 네이버는 보수편향, 구글은 진보편향, 다음은 미세한 진보편향이 있다고 판단됩니다.
단순히 빅데이터를 점유율 가중합산 하는 것보다 진보/보수편향성 왜곡율을 보정해주고 계산하면 좀 더 정확하겠다는 생각을 하게 됩니다.
◀ 보수/진보 왜곡율=(보수후보 검색량/진보후보 검색량)/(보수후보 실득표율/진보후보 실득표율)
4.7보궐선거의 데이터를 바탕으로 위와 같은 방식으로 진보/보수 왜곡율을 계산해보면
◀ 네이버: 보수편향 10% (1.1059)
◀ 구글: 진보편향 25% (0.7644)
◀ 다음: 진보편향5%(0.9595)
위와 같은 수치가 왜곡률이 나오며 이것을 이용하여 원 빅데이터(Raw Data)에 적용해서 보정을 합니다.
◀ 윤석열 보정 = (윤석열+이재명)*윤석열/(윤석열+이재명*왜곡률)
◀ 이재명 보정 = 윤석열+이재명-윤석열 보정
5. 이슈 왜곡보정
우리가 빅데이터를 통해서 지지율을 추종하는 분석결과를 내놓으려 하는데 이것은 별다른 특종 이슈가 없는 평상시 상태에서 각 후보의 관심도=검색량=지지율, 이렇게 가정하고 있기 때문에 특종이슈에 의해 단발성으로 튀는 검색량은 노이즈로 판단하는 것입니다
예를 들어, 2월~3월초에 네 명의 대선후보 검색량 추이입니다.
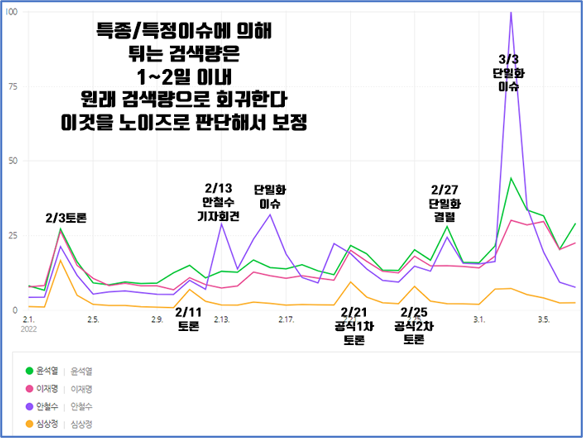
심상정 후보의 경우를 보면 토론이 있을 때마다 검색량이 튀어올랐다가 다시 원래자리로 회귀합니다. 안철수 후보의 기자회견, 단일화 이슈 때에도 검색량이 튀어올랐다가 다시 원래자리로 회귀합니다. 이것을 이슈왜곡이라고 판단하여 보정을 했습니다. 즉 특종 이슈 없는 평상시 검색량이라는 가정하에 빅데이터의 검색량이 각 후보의 지지율을 추종한다는 것입니다.
- 이 분석방법은 긍정/부정이슈를 가려내지 못합니다. 해당후보의 검색량은 부정적 이슈에 의해서도 올라갈 수 있기 때문입니다.
- 진보/보수 왜곡률 보정은 양자대결에서 의미가 있는데 심상정후보가 포함된 상황에서 윤설열 vs 이재명후보의 검색량만 보정을 했습니다. 분석방법 설계의 한계입니다.
- 데이터 분석이 기준이 되는 기준점이 4.7서울시장 보궐선거 데이터 하나입니다. 많은 데이터가 쌓인 분석방법은 아닙니다.
- 이슈왜곡 보정은 완벽하지 못하며, 주관적 판단에 의해 데이터가 오염될 가능성이 있습니다
- 포털사이트의 검색량이 실제 득표율과 직접적인 연관성이 있음을 확신하지 못합니다.
일단 이런 분석방법으로 4.7보궐선거를 분석했을 때 실제 득표율과 가깝게 수렴했다는 것은 이 방법이 아주 허무맹랑한 방법은 아니라는 판단입니다. 100%완벽한 방법은 아니니 여론조사 결과와 병행해서 보고 참고 사항 정도로 봐주시면 될 것 같습니다.
6. 서울시장선거: 송영길 후보, 오세훈 후보 비교

※ 지난 한달동안 송영길 후보와 오세훈 후보의 빅데이터 그래프입니다.
네이버 데이터랩
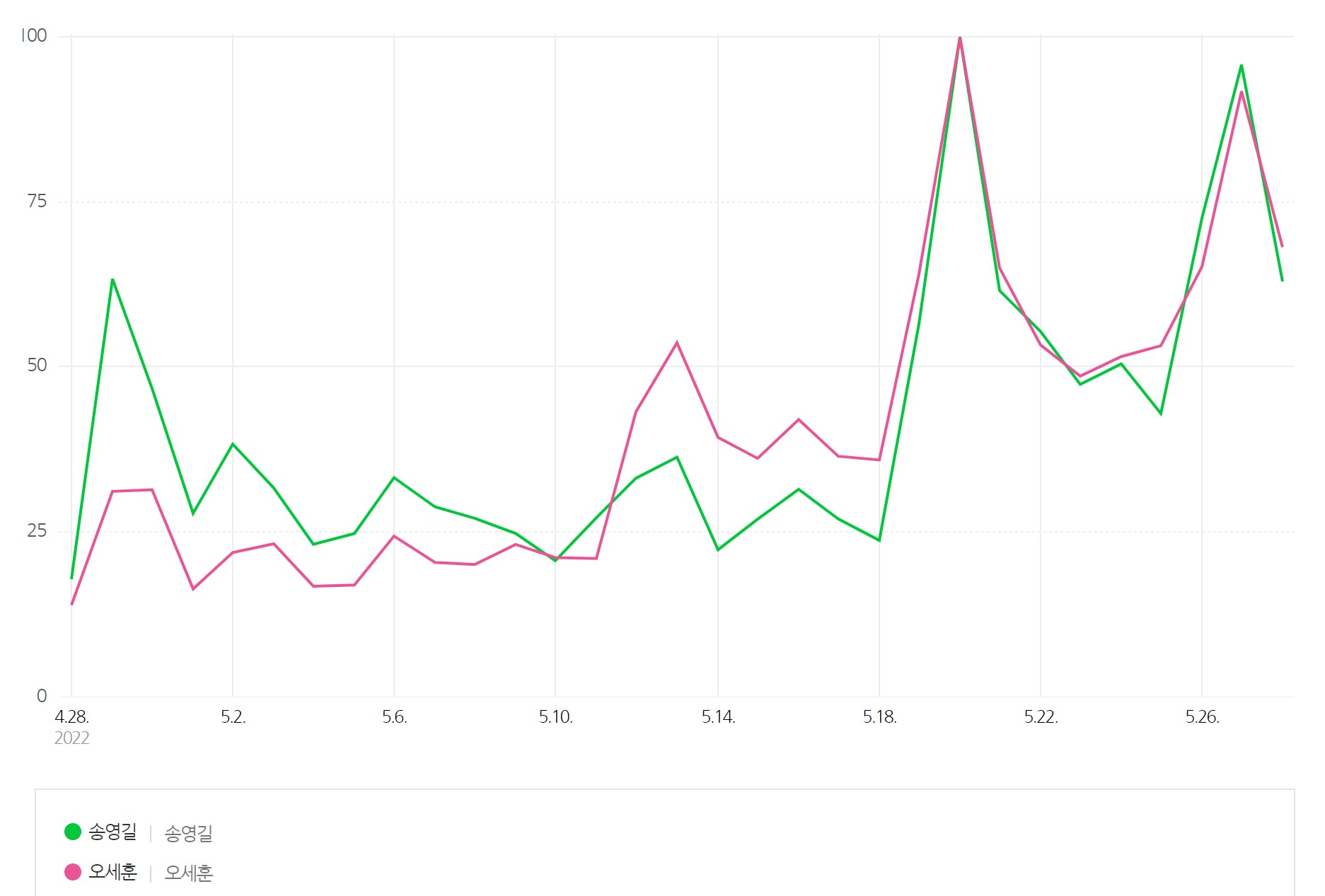
구글트렌드

카카오데이터트렌드
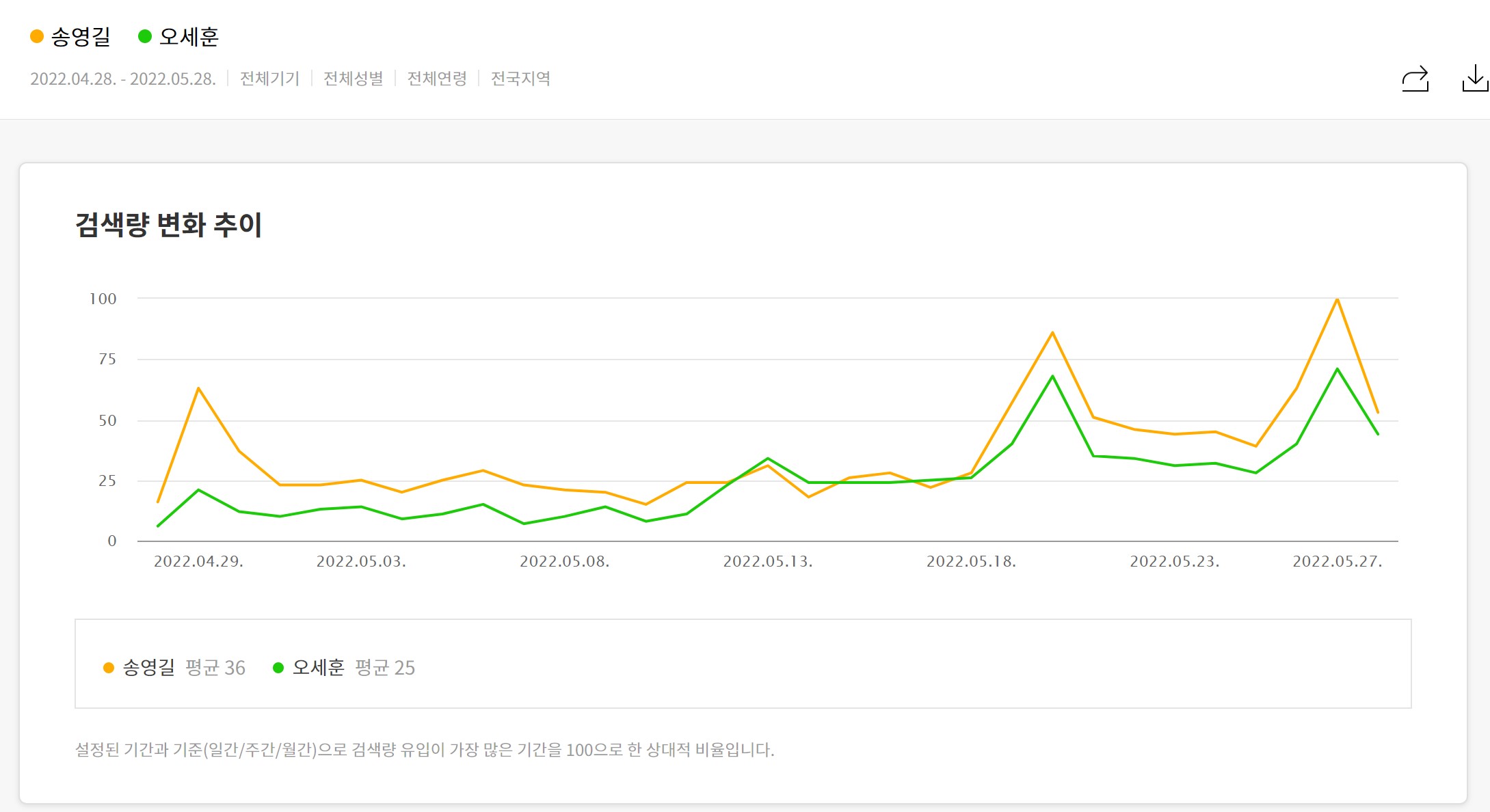
결론
오세훈 후보가 송영길 후보에 10% 이상 앞서는 결과를 보여주는 일반 여론조사와는 달리, 빅데이터는 두 후보가 박빙의 승부를 펼치고 있음을 말해줍니다. 위의 빅데이터 분석법으로 빅데이터 점유율과 편향 왜곡율을 계산하면 오히려 송영길 후보가 약간 앞서고 있는 상황입니다. 끝까지 포기하지 맙시다.
"투표하면 이깁니다!"




댓글